Browser-Based AI for Geographic Search: A Transformers.js Experiment
For busy humans
This experiment tests whether a small language model can run entirely in the browser and answer geographic questions on a map. Using Transformers.js and LaMini-Flan-T5, the demo works offline after download, keeps data local, and reached 76 percent accuracy on 25 test prompts.
I wanted to explore the current state of small language models running natively in the browser. The promise is compelling: privacy (no data leaves your device), zero API costs, and potential for offline-first applications. To test this, I built a natural language map navigator where you can ask questions like "which country is famous for pizza?" and watch the map fly to Italy.
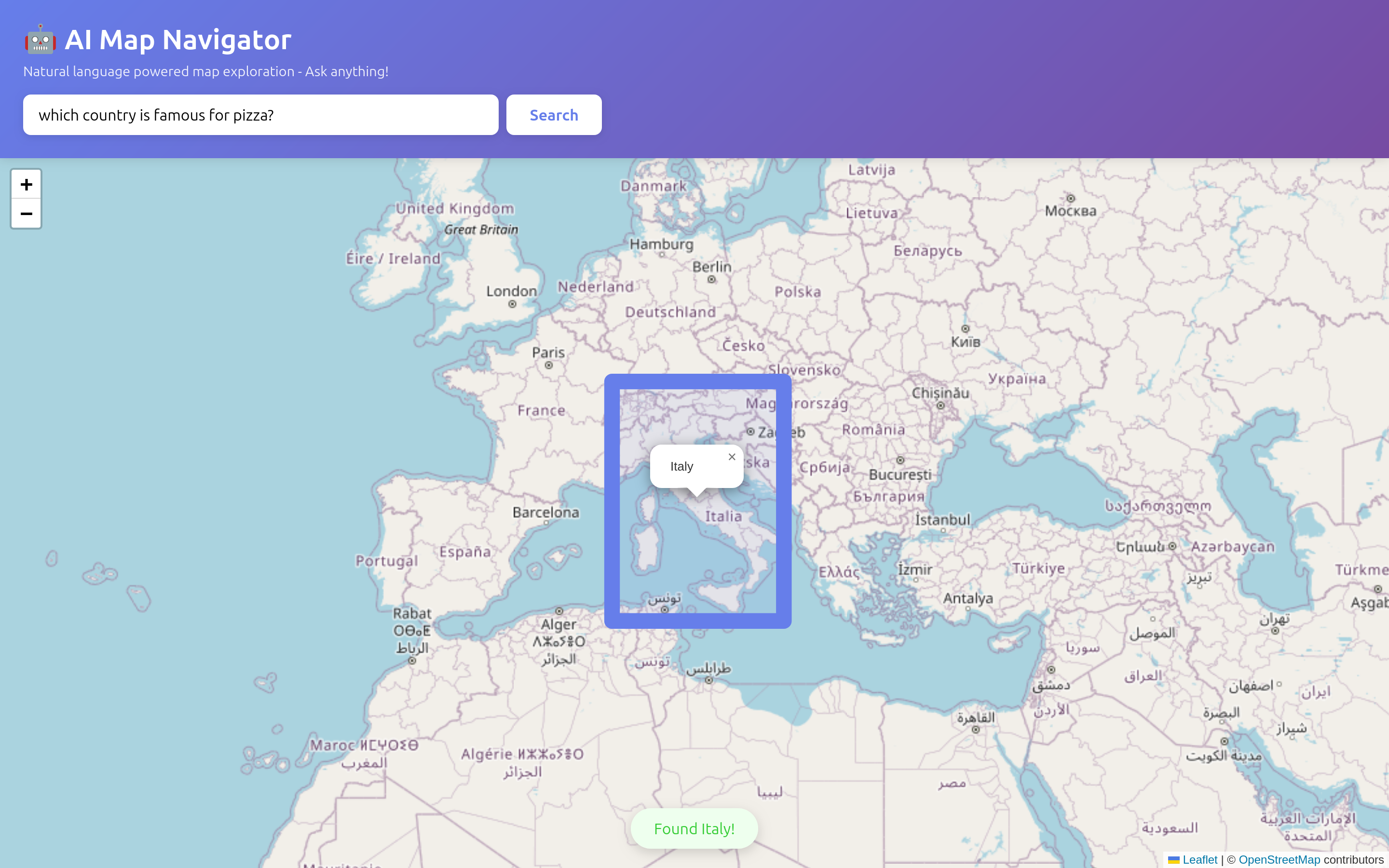
The Model Selection Problem
I built a test interface to compare 9 different Hugging Face models available through Transformers.js. The results were sobering: only 1 of 9 models actually worked for this use case.
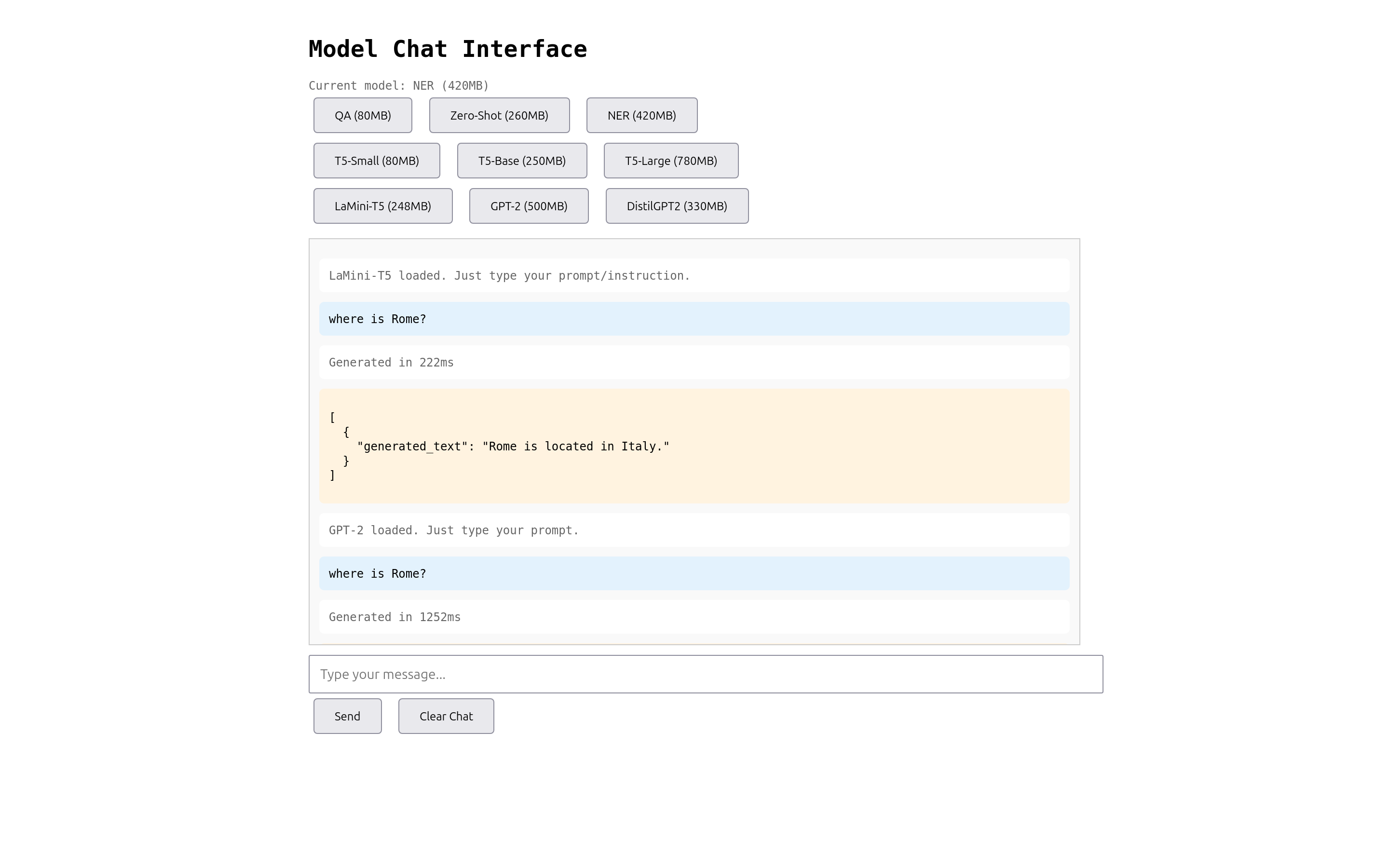
Here's what I found when asking "where is Rome?":
| Model | Size | Result |
|---|---|---|
| LaMini-Flan-T5-248M | 248MB | "Rome is located in Italy." (222ms) |
| GPT-2 | 500MB | "The Roman Empire was founded in the year AD 732..." (hallucination) |
| DistilGPT2 | 330MB | Empty newlines only |
| T5-Small | 80MB | "Rome" (loses the question context) |
| T5-Base | 250MB | Failed to load (JSON parse error) |
| T5-Large | 780MB | Failed to load (401 Unauthorized) |
| Zero-Shot | 260MB | Failed to load (JSON parse error) |
| NER | 420MB | Returns entity labels, not answers |
| QA | 80MB | Requires context passage (wrong task type) |
The LaMini-Flan-T5-248M model emerged as the only viable option. It's an instruction-tuned model that understands questions and generates appropriate answers. Bigger models like GPT-2 actually performed worse, producing hallucinations or repetitive garbage output.
The Two-Stage Extraction Pipeline
Even with the right model, there was a problem. When asked "where is Brazil?", the model responds with "Brazil is a country located in South America." - which is correct, but my country matching code couldn't extract "Brazil" from that sentence.
The solution was a two-stage pipeline:
// Stage 1: Ask the question
prompt: "Answer with only a country name: where is Brazil?"
response: "Brazil is a country located in South America."
// Stage 2: Extract country name (only if response has >2 words)
prompt: "Extract only the country name from this text: Brazil is a country located in South America"
response: "Brazil."This approach improved accuracy significantly. The model sometimes gives concise answers ("Egypt.", "China.") and sometimes verbose ones ("Rome is located in Italy."). The second stage handles the verbose cases.
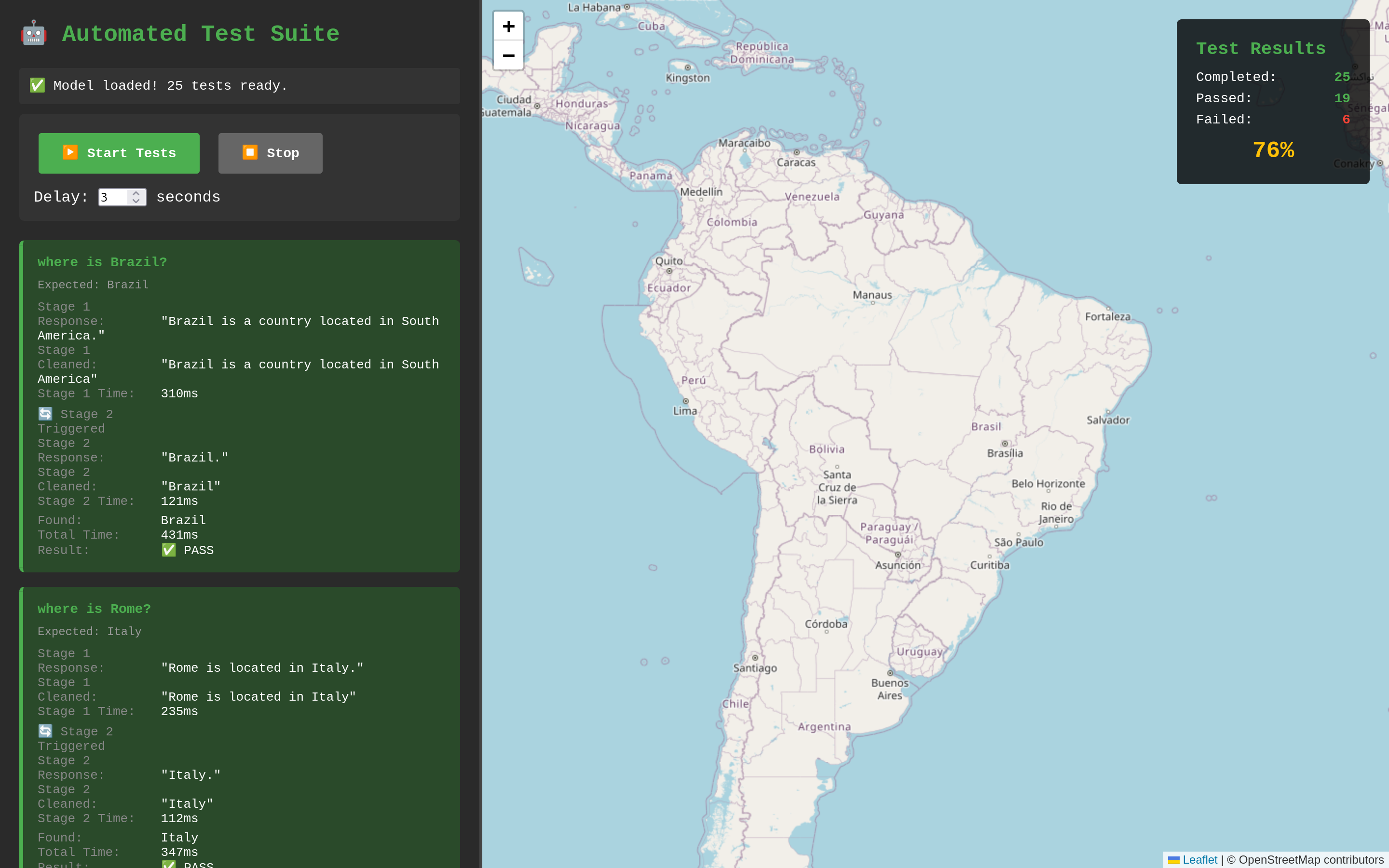
Results: 76% Accuracy
I created 25 test cases covering landmarks, cities, and cultural associations. The final accuracy was 76% (19/25 passed). Looking at the failures reveals interesting patterns:
| Query | Expected | Got | Analysis |
|---|---|---|---|
| famous for windmills | Netherlands | Denmark | Debatable - both valid |
| famous for wine | France | Italy | Debatable - both valid |
| famous for sauna | Finland | Japan | Wrong - Japan has onsen, not sauna |
| famous for K-pop | South Korea | Japan | Wrong - conflates Asian pop culture |
| famous for tango | Argentina | Mexico | Wrong - conflates Latin culture |
| famous for paella | Spain | Mexico | Wrong - doesn't know Spanish cuisine |
The failures aren't random - they show the model's knowledge gaps. It conflates regional cultures (Latin America, East Asia) and has weak coverage of some European traditions. Two of the "failures" (windmills, wine) are arguably correct answers.
What I Learned
Transformers.js just works. The API is intuitive and I didn't need to spend much time in the documentation. When models work, they work well.
Model selection is severely limited. Most Xenova-ported models either fail to load or produce unusable output. You need to test extensively before committing to a model.
250MB is the minimum viable size for instruction-following tasks. Smaller models (T5-Small at 80MB) lack the capacity to understand and respond to questions properly.
Loading times are becoming acceptable. With 4G/5G connections, a 250MB model download is reasonable for production use. Browser caching means subsequent loads are instant.
Prompt engineering matters. The main challenge wasn't the code - it was finding the right prompt format to get clean, usable answers. The two-stage pipeline emerged from iterating on this.
Try It Yourself
- Main Application - Ask geographic questions
- Model Chat Interface - Compare different models
- Automated Test Suite - Run the 25-query benchmark
Future Possibilities
There's significant room for improvement:
- Fine-tuned model: A model trained specifically on geographic data (countries, cities, landmarks, cultural associations) could be much smaller and more accurate
- Voice input: Web Speech API integration for spoken queries
- Expanded dataset: More countries, cities, and richer cultural/folklore data
I don't yet see a practical production application for NLP + mapping, but the technology is maturing fast. The combination of browser-based ML, offline capability, and zero API costs opens interesting possibilities for privacy-first applications.
Acknowledgments
This project was built in 3 hours using OpenCode with Claude Opus 4.5 - a testament to how AI-assisted development can accelerate prototyping and exploration.