Raster Transformation with GDAL: Sequential vs. Parallel for Optimal Performance
For busy humans
This article compares sequential and parallel GDAL workflows for generating NDVI rasters from Sentinel-2 tiles. Processing ten tiles one by one took 28.547 seconds; running the same tile operations in parallel took 11.892 seconds, showing how simple parallelism can speed up independent raster jobs.
Sequential and parallel programming are two different approaches, each with its own advantages and considerations, especially when dealing with tasks like raster transformation using GDAL.
Loop programming involves iterating through data sequentially, performing operations step by step. It’s straightforward and easy to understand, making it accessible for many developers. On the other hand, parallel programming involves breaking tasks into smaller parts and executing them simultaneously, often speeding up processes significantly but requiring careful management of resources and potential synchronization issues.
Performance Comparison
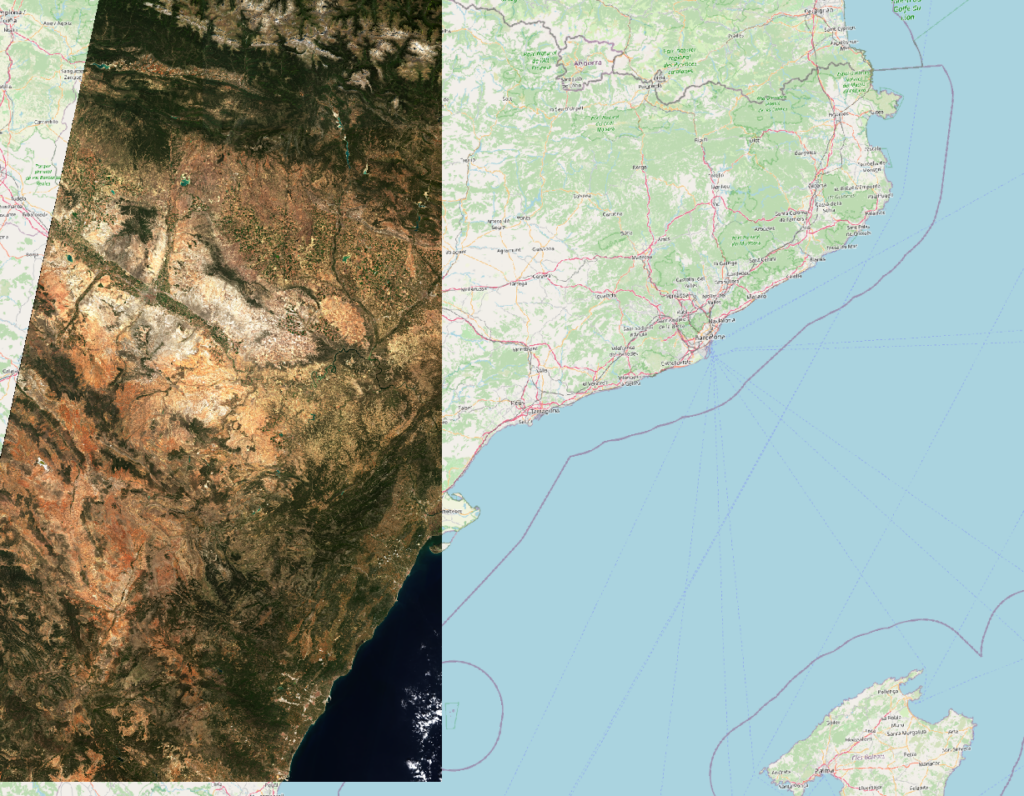
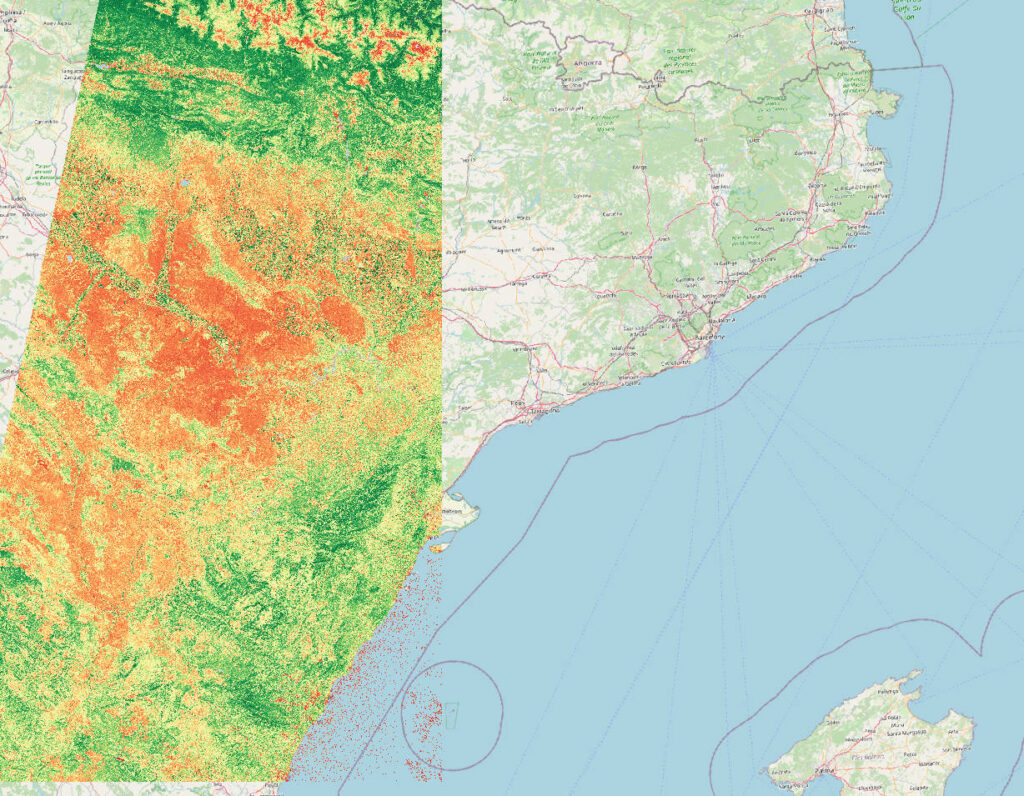
We are going to generate NDVI GeoTiffs from the Copernicus Sentinel-2 bands 04 (red) and 08 (NIR-1).
The data we are using represents a zone next to Barcelona.
The images from Copernicus are taken on October 12th, 2023.
The input files come from ten Sentinel-2 tiles.
The tile size is 10,980 × 10,980 pixels.
The band tiffs weight from 8 to 253 MB.
Here the list of the ten tiles we are using:
- S2A_30TWK_20231012_0_L2A
- S2A_30TWL_20231012_0_L2A
- S2A_30TXK_20231012_0_L2A
- S2A_30TXL_20231012_0_L2A
- S2A_30TXM_20231012_0_L2A
- S2A_30TXN_20231012_0_L2A
- S2A_30TYK_20231012_0_L2A
- S2A_30TYL_20231012_0_L2A
- S2A_30TYM_20231012_0_L2A
- S2A_30TYN_20231012_0_L2A
The True Color visualization of these tiles:
Sequential script
I’ve created a script called “sequential.sh”.
#!/bin/bash
# Directory containing Sentinel-2 image files
export base_dir=/some_dir
# Directory where NDVI output will be saved
export destination_dir=/some_other_dir
# Choose the date that matches the downloaded tiles
export date=20231012
# Get unique tiles from files in base_dir
tiles=$(ls $base_dir | grep $date | grep '.tif$' | cut -d "." -f 1 | cut -d "_" -f 1-3 | sort -u)
# Loop through each unique date
for tile in $tiles; do
# Define file paths for B04, B08, and NDVI for the current date
b04="${base_dir}/${tile}.B04.tif"
b08="${base_dir}/${tile}.B08.tif"
ndvi="${destination_dir}/${tile}.ndvi.tif"
# Calculate NDVI using gdal_calc.py tool
gdal_calc.py --overwrite -A "${b04}" --A_band=1 -B "${b08}" --B_band=1 --calc="(B-A)/(B+A)" --outfile="${ndvi}"
done
#generate a virtual raster to visualize in QGIS
gdalbuildvrt ${destination_dir}/${date}.ndvi.vrt $(find $destination_dir | grep .tif | grep $date )
Bash has a timing feature called “time”. We’ll use it to measure the performances.
$ time sequential.sh
...
real 0m28.547s
user 0m29.108s
sys 0m17.317sParallel script
Here the second script called “parallel.sh”
#!/bin/bash
# Directory containing Sentinel-2 image files
export base_dir=/some_dir
# Directory where NDVI output will be saved
export destination_dir=/some_other_dir
# Choose the date that matches the downloaded tiles
export date=20231012
# Extract unique dates from files in base_dir
tiles=$(ls $base_dir | grep $date | grep '.tif$' | cut -d "." -f 1 | cut -d "_" -f 1-3 | sort -u)
# Define function to calculate NDVI for a given date
ndvi(){
tile=$1
echo $date
# Define file paths for B04, B08, and NDVI for the current date
b04="${base_dir}/${tile}.B04.tif"
b08="${base_dir}/${tile}.B08.tif"
ndvi="${destination_dir}/${tile}.ndvi.tif"
# Calculate NDVI using gdal_calc.py tool
gdal_calc.py --overwrite -A "${b04}" --A_band=1 -B "${b08}" --B_band=1 --calc="(B-A)/(B+A)" --outfile="${ndvi}"
}
# Exporting the 'ndvi' function to be used with parallel processing
export -f ndvi
# Execute the 'ndvi' function in parallel for each date using 'parallel' command
parallel ndvi ::: $tiles
#generate a virtual raster to visualize in QGIS
gdalbuildvrt ${destination_dir}/${date}.ndvi.vrt $(find $destination_dir | grep .tif | grep $date )
When running the script with the “time” function.
$ time parallel.sh
...
real 0m11.892s
user 1m46.785s
sys 0m8.576sThe resulting NDVI image:
Considerations
The evident difference between parallel programming and sequential programming on a modern multi-threaded processor is clear.
In our case we can process the 10 files in a fraction of the time (11.892 sec vs 28.547 sec). An increase in speed by 240%.
With a big dataset to process the impact would be even higher.
The advantage increases the more data we have to process.
Implementation Challenges
Pixel-by-Pixel Calculation Suitability
Not all aspects of a geospatial pipeline can be seamlessly parallelized. While pixel-by-pixel calculations often lend themselves well to parallel processing, other operations might pose challenges.
Handling Boundary Features
Features that initiate in one tile and extend into another can complicate or entirely change the process of merging resulting datasets. This boundary handling becomes a crucial consideration during parallel processing.
Limitations in GDAL Packages
Certain GDAL packages are coded in Python and may not inherently support parallel execution. Understanding the limitations of these packages is vital when designing a parallel processing workflow.
Optimization with Virtual Rasters
Efficiently managing large datasets involves considering strategies like processing smaller tiles separately and then integrating them into a virtual raster. However, this strategy might not be universally applicable, especially with complex feature interactions.
Conclusion
Incorporating parallelism into geospatial workflows offers significant performance gains, yet it demands a nuanced understanding of data structure, feature interactions, and limitations within the processing tools employed.